ProofMeister, my first web app, is up. Its main use case is philosophy and computer science students cheating on their homework, but well, it was still fun to make. I made it with python and django, but I'm thinking I might switch over to the Ruby world for the next project. Seems to be a more widely-used set of tools.
Also, since my last post, Google has integrated my ideas into GMail, so it's nice to know they're reading my blog.
Wednesday, July 17, 2013
Monday, February 27, 2012
The problem with email is it's just too general of a means of sending information to human beings. Spam filters are great, but I get a lot more kinds of email than just spam and non-spam. I get emails from my family, emails from automated systems at school, emails from daily deal sites, emails from my bank, and emails from my employer. Also, sometimes, I get spam from my family. Am I the only one who hates the fact that all these things go into the same place? I know roughly what time of day Groupon emails go out, and when I feel my phone vibrate at that time I tend to ignore it. The fact that I've subconsciously developed a mental filter on my phone notifications means that somebody's doin' it wrong.
I'm not trying to pick on Groupon; it's a great service, but the signal-to-noise ratio seems to be getting pretty bad. Bad enough that I'm really pretty torn about whether to unsubscribe, or attempt to train my spam filter to distinguish useful and useless Groupon deals. (Speaking of useless Groupon offers: I'm pretty sure Groupon knows my gender, so why do I get SOOOO MANY day spa, tanning, massage, and pedicure type offers?)
GMail's priority inbox is a step in the right direction, but why not just apply the pattern recognition it uses to an arbitrary number of "mailboxes" instead of having to set up highly specific rules or filters. Don't tell me the same system that recognizes spam can't also differentiate all the "daily deal" emails everyone gets and spin them off to a daily deals folder automatically. Also, don't tell me to set up mail filters or rules. It can and should be easier than that. It should be zero set-up, just like spam filtering. I shouldn't have to decide what I want the categories to be, either. They should just appear, based on what kind of stuff I'm getting. Emails are highly archetypal.
And imagine if some smartphone OS producer (that also happens to be an email service provider with a nifty little superset of IMAP) used this classification system to automagically modify the notification behavior of their smartphone email clients based on how a particular message gets classified. I want my phone to vibrate when my mom emails me. I don't want it to vibrate when Groupon emails me. Heck, I don't even want Groupon mail to show up in the little red number in the Mail.app icon. But I don't want to flag Groupon as spam either. Cuz Groupon isn't spam. It's useful. Just not THAT useful.
On the other hand, maybe it's not such a bad thing that all this email goes to the same place. Imagine Siri a couple years from now, where she reads my emails and tells me when I've got a bill to pay. Or that Groupon has a sweet deal that doesn't involve some kind of massage or spa treatment. If we want to live in a world where we have humble personal assistants, it's certainly going to be useful for them to "know" things about us. I suspect that data-mining the fire hose of information that comes into my email account is going to be a lot better way for Siri to learn about me than trying to standardize some kind of API for app developers to talk to Siri. Not that an API is an inherently bad idea, it's just a bad idea to let the app developers have too much say in what it means for Siri to be "personal." They already get to do that with my email box, and Groupon is a perfect example of why that's a problem.
Another perk: the only company that might be able to claim IP ownership over a method or technique for data mining email is, thankfully, the one company out of the three-and-a-half players in the smartphone world that's not likely to be a patent bully.
I'm not trying to pick on Groupon; it's a great service, but the signal-to-noise ratio seems to be getting pretty bad. Bad enough that I'm really pretty torn about whether to unsubscribe, or attempt to train my spam filter to distinguish useful and useless Groupon deals. (Speaking of useless Groupon offers: I'm pretty sure Groupon knows my gender, so why do I get SOOOO MANY day spa, tanning, massage, and pedicure type offers?)
GMail's priority inbox is a step in the right direction, but why not just apply the pattern recognition it uses to an arbitrary number of "mailboxes" instead of having to set up highly specific rules or filters. Don't tell me the same system that recognizes spam can't also differentiate all the "daily deal" emails everyone gets and spin them off to a daily deals folder automatically. Also, don't tell me to set up mail filters or rules. It can and should be easier than that. It should be zero set-up, just like spam filtering. I shouldn't have to decide what I want the categories to be, either. They should just appear, based on what kind of stuff I'm getting. Emails are highly archetypal.
And imagine if some smartphone OS producer (that also happens to be an email service provider with a nifty little superset of IMAP) used this classification system to automagically modify the notification behavior of their smartphone email clients based on how a particular message gets classified. I want my phone to vibrate when my mom emails me. I don't want it to vibrate when Groupon emails me. Heck, I don't even want Groupon mail to show up in the little red number in the Mail.app icon. But I don't want to flag Groupon as spam either. Cuz Groupon isn't spam. It's useful. Just not THAT useful.
On the other hand, maybe it's not such a bad thing that all this email goes to the same place. Imagine Siri a couple years from now, where she reads my emails and tells me when I've got a bill to pay. Or that Groupon has a sweet deal that doesn't involve some kind of massage or spa treatment. If we want to live in a world where we have humble personal assistants, it's certainly going to be useful for them to "know" things about us. I suspect that data-mining the fire hose of information that comes into my email account is going to be a lot better way for Siri to learn about me than trying to standardize some kind of API for app developers to talk to Siri. Not that an API is an inherently bad idea, it's just a bad idea to let the app developers have too much say in what it means for Siri to be "personal." They already get to do that with my email box, and Groupon is a perfect example of why that's a problem.
Another perk: the only company that might be able to claim IP ownership over a method or technique for data mining email is, thankfully, the one company out of the three-and-a-half players in the smartphone world that's not likely to be a patent bully.
Saturday, December 17, 2011
Learning Goals
Math:
-more statistics
-all about bayesian inference
-linear algebra
Programming:
-more R
-a functional language (probably Scheme or Haskell)
-Objective C
-More Java, because that's what UA teaches, but meh.
-web backend stuff.
Hacking Skillz:
-vi(m)
-more regular expressions
Classes to take:
ISTA 410: Bayesian inference
ISTA 450: Artificial Intelligence
ISTA 421: Machine Learning (not sure if class exists yet)
CSC 345: Discrete Structures
CSC 445: Algorithms
To Do:
-Finish ISTA degree leaning towards mathematical/computational side.
-CSC minor, take the classes I want, don't worry about completing a second major.
-Section Lead ISTA 130
-Continue to be involved in SISTA
-Get a good internship
-Keep learning stuff on Khan Academy
-Take opportunities to talk to smart people
-Try not to be too tied to short-term job with attractive perks if it starts to get in the way of anything else on this list.
Wednesday, December 14, 2011
Post Facto ISTA 301 Blog
Harold Cohen's talk for the SISTA colloquium was pretty interesting. In particular, I was intrigued by the relative simplicity of his color selection algorithm. Essentially, he used a random number generator, or some kind of mathematical pattern to select 9 numeric values, which he rescaled to become values (no pun intended) for the 'V' component of the HSV color model. From those 9 values, he randomly selected a high, mid, and low that ended up serving as the bright, medium, and dark parts of AARON's paintings.
What's interesting about this is that I have some semi-formal education in fine arts painting, and this very much echoes what I was taught. Highlight, Halftone, and Shadows. I literally have charcoal drawings of nine squares in various shades of gray.
However, in oil paint, I was taught to create my halftones and shadows not by adding black, but by adding a complimentary color. This had the effect of producing more neutral-looking halftones. I'm not really very well-read in color theory, but I'm curious how this method would be replicated algorithmically.
In my third assignment, I built a processing application that drew very simple Mark Rothko style images. Perhaps like rothko, the composition was deliberately simple; my focus was on building a color selection algorithm that was decently good at finding colors that look good with each other. All in all, I'd say my app gets it right maybe 1/3 of the time. And I think the problem is that I can't create truly natural-looking color selections when I'm only varying the V in HSV. I need to figure out what to do with the S at the same time.
And I have no idea how, because I don't know anything about color theory.
What's interesting about this is that I have some semi-formal education in fine arts painting, and this very much echoes what I was taught. Highlight, Halftone, and Shadows. I literally have charcoal drawings of nine squares in various shades of gray.
However, in oil paint, I was taught to create my halftones and shadows not by adding black, but by adding a complimentary color. This had the effect of producing more neutral-looking halftones. I'm not really very well-read in color theory, but I'm curious how this method would be replicated algorithmically.
In my third assignment, I built a processing application that drew very simple Mark Rothko style images. Perhaps like rothko, the composition was deliberately simple; my focus was on building a color selection algorithm that was decently good at finding colors that look good with each other. All in all, I'd say my app gets it right maybe 1/3 of the time. And I think the problem is that I can't create truly natural-looking color selections when I'm only varying the V in HSV. I need to figure out what to do with the S at the same time.
And I have no idea how, because I don't know anything about color theory.
Thursday, December 8, 2011
ISTA 301 Blog: Awesome Visualizations I've been saving for a Blog Post
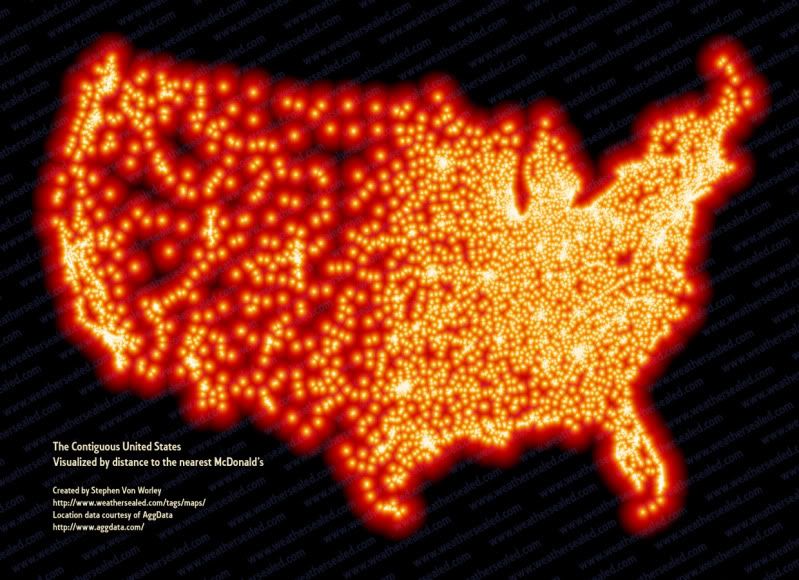
The darker spots on this map are the spots that are furthest from a McDonalds. Purdy!
ISTA 301 Blog: More Probabilistic Fun.
More potential has emerged after spending an evening at Time Market with a lot of literature grad students. First of all, the text generator is great fun when fed James Joyce's interminable masterpiece, Ulysses, as source material. Scraping the bottom of the barrel for technology related puns, this one has been christened "Joyce-stick." Its first words are pictured here, along with some of the aforementioned grad student commentary.

I mean, it's not really a quotation, nor does it contain any actual prose from Beck that is more than a few words long, however it also contains no original material. It is "analysis," but only in a very mechanical sense. Would it be protected under fair use? As far as I know, nothing like this has ever gone to court (though Beck is not busy defending free speech, he has proven notably litigious.)
Interesting question, no?
But the true inspiration of the night came only after a solid hour of beer sipping: Why not seed the text generator with the words of that infamous mad prophet of the airwaves, Glenn Beck?
Well, we did. And we had dramatic readings right there in Time Market that grew increasingly loud after another round of drinks were ordered. Here's an excerpt:
We learned about Microsoft. What I'm starting to take the set apart and this was a warning in 1939 to the American people. Thank you for sending it. Think how many people even know that? And how it was turned around and it can be used for good. But when it comes to a very hard left groups like Free Press are advocating for. Eric Schmidt, the former CEO talked about where he sees the future. Same thing is happening, America, with your food. Thirty-eight percent of the households even watching her for the next block. And that is the key. That it is that we believe in evil. The only answer to millions in the same things from all over the country was two years ago -- me and you as individuals that listen to the experts. They're usually sells in a year. I mean, I just -- I like live television who told you yet that I've said something wasn't done. You got to print more money. Push it out. Today, it closed at over $1500. What was it -- $1511? That's insane. You would think you come to Washington, D.C. and now, they have been loose with power do. These elitist dopes in the media who are celebrating, I waited for a season because you are being lied to. And you need to know what you are thinking individuals that listen to our programs. Not all of these scenes -- put the six other currencies to determine its value internationally. Six currencies to determine its value internationally. Six currencies and it's the Fed. And that's not good. I think in Australia and the on the road Khilafah or caliphate on the caliphate. That's why it doesn't make sense because oil has to be purchased with dollars -- people holding euros have to sell to the people who hate it here do not believe me when I was only on the air for one hour every day at 5:00. This is where Google's street view cars downloaded e-mails, passwords, and other information. They're because this is the NewsCorp building. This is not difficult to figure out some things, maybe a little longer than all of us, and you try to think, what is it I want to show you a few things." She just happens to be running for vice president at the time." He says and he predicts, I saw this video and think he was serious, that every young person will one day be entitled to automatically change his or her name on reaching adulthood to disown youthful hijinks stored on their friends' so-called media sites. And let's not forget this super, super classic, quote, "We know roughly who you are, and all of us, and you think I have to. I'm not leading any boycott. I hate boycotts. You do with your time and information. They are working really, really closely with the government and that`s a spooky thing. And we've done amazing people. And I have made amazing people. And I have done that lately? Let me keep this brief. Tonight America, here`s what you are the answer, and that we must have dollars.I did get curious though, as I was copying program transcripts off of Beck's web site and viewing the copyright notification that it obnoxiously embeds in text as you copy it to the clipboard. If I were to data mine Beck's site and build a probabilistic map of his prose, and then, say, post my program and the accompanying database online, would this be considered a copyright infringement?
I mean, it's not really a quotation, nor does it contain any actual prose from Beck that is more than a few words long, however it also contains no original material. It is "analysis," but only in a very mechanical sense. Would it be protected under fair use? As far as I know, nothing like this has ever gone to court (though Beck is not busy defending free speech, he has proven notably litigious.)
Interesting question, no?
ISTA 301 Blog: Briannatomaton
Part of one of my Computer Science 227 assignments was to implement a probabilistic text generator. That is, a program that scans through a large text file, finds patterns in which letters tend to follow which other letters most often, and then generates a new text semi-randomly based on those probabilities. It's loads of fun, as it tends to produce mad-libs style nonsense but in a prose style similar to that of the text that fed it.
Oddly enough, as an ISTA student, I'd already been exposed to this idea in Paul Cohen's class a few semesters ago, and shortly before the 227 assignment was posted, I joked with Brianna about setting up a text generator based on her writing. When it turned out that the final project in one of my classes was to implement this very idea, I was ecstatic.
What it does is read every substring of n length in a large text and then builds a hash table containing list of every character that follows that substring, weighted according to the frequency of its occurrence. I use Google Voice for my text messages, so I was able to download an HTML archive of all the text messages Brianna has sent me in the last 6 months. 15 minutes and a little studying up on regular expressions later, and I had removed all of my own responses as well as all the HTML tags and just and a solid plaintext block of Brianna's texts. I fed this, along with some of her blog and a few papers she wrote as an undergrad into a gigantic text file which totalled about 82,000 words.
Briannatomaton was born. I modified the code slightly so that I could force it to "seed" each randomly generated blurb with a word or two at the beginning, which let me have it "talk to" specific names that occur in the text I fed into it. Why would I want to do that? Simple. Because Briannatomaton got her own facebook page.
Oddly enough, as an ISTA student, I'd already been exposed to this idea in Paul Cohen's class a few semesters ago, and shortly before the 227 assignment was posted, I joked with Brianna about setting up a text generator based on her writing. When it turned out that the final project in one of my classes was to implement this very idea, I was ecstatic.
What it does is read every substring of n length in a large text and then builds a hash table containing list of every character that follows that substring, weighted according to the frequency of its occurrence. I use Google Voice for my text messages, so I was able to download an HTML archive of all the text messages Brianna has sent me in the last 6 months. 15 minutes and a little studying up on regular expressions later, and I had removed all of my own responses as well as all the HTML tags and just and a solid plaintext block of Brianna's texts. I fed this, along with some of her blog and a few papers she wrote as an undergrad into a gigantic text file which totalled about 82,000 words.
Briannatomaton was born. I modified the code slightly so that I could force it to "seed" each randomly generated blurb with a word or two at the beginning, which let me have it "talk to" specific names that occur in the text I fed into it. Why would I want to do that? Simple. Because Briannatomaton got her own facebook page.
Subscribe to:
Posts (Atom)